数据采集
本章节使用nut_stm32_f103c8作为Nut(其出厂时已经包含Gloden固件供演示、测试使用),演示基础的数据采集流程的部署。使用Jupyter作为开发环境(使用pip install cracknuts[jupyter]进行安装)。
本章节内容会对必要的Jupyter基础操作进行描述,如果您对Jupyter比较熟悉可以跳过。需要了解更多有关Jupyter的内容可以访问Project Jupyter Documentation 。
创建Jupyter记事本
在CrackNuts环境中执行命令cracknuts lab 或 jupyter lab打开Jupyter环境。
Jupyter默认安装情况下是英文,如果您需要中文环境可以执行pip install jupyterlab-language-pack-zh-CN命令安装中文语言包,并在启动Jupyter后在Settings -> Language中进行切换。
双击Jupyter启动页的笔记本-Python3(ipykernel)创建新笔记
连接设备
在新建的笔记文件中,插入如下代码并执行(可以在选中该编辑框后点击上方的运行按钮执行或者Crtl + Enter快捷键执行)创建CrackerS1设备对象用以连接设备使用。
# 引入依赖
import cracknuts as cn
# 创建 cracker
s1 = cn.cracker_s1('192.168.0.15')
192.168.0.15地址需要根据你的实际IP进行设置,(192.168.0.10为CrackerS1设备默认出厂IP地址)。
准备设备确保设备与上位机计算机能够通信,插入如下代码并执行进行设备连接,连接成功后代码会很快执行完成并无错误输出:
s1.connect() # 连接设备
也可以使用 s1.connect(force_update_bin=True, force_write_default_config=True) 进行连接,
force_update_bin=True参数表示强制更新设备固件force_write_default_config=True参数表示强制写入默认配置。
此方法可以使得设备每次连接时都重置为初始状态,方便调试,一般使用时,可以直接执行connect()方法进行连接。
如果设备连接不成功将出现如下错误日志:

-
此时可以先检查设备是否启动,并且LED显示屏上是否已经显示IP地址

-
如果正常显示了IP地址,并且设备与上位机计算机通过有线网卡直连,可检查配置上位机有线网卡IP地址是否配置为了同网段的IP,如:可配置为
192.168.0.11/24。
创建控制流程
控制流程指的是上位机采集数据的一个固定执行顺序,上位机中使用Acquisition类代表。以下代码是一段用于CrackerS1 - STM32 设备的AES能量轨�迹采集代码,
import random
import time
from cracknuts.cracker import serial
cmd_set_aes_enc_key = "01 00 00 00 00 00 00 10"
cmd_aes_enc = "01 02 00 00 00 00 00 10"
aes_key = "11 22 33 44 55 66 77 88 99 00 aa bb cc dd ee ff"
aes_data_len = 16
sample_length = 20000
def init(cracker):
cracker.nut_voltage_enable()
cracker.nut_voltage(3.3)
cracker.nut_clock_enable()
cracker.nut_clock_freq('8M')
cracker.uart_io_enable()
cracker.osc_sample_clock('48m')
cracker.osc_sample_length(sample_length)
cracker.osc_trigger_source('N')
cracker.osc_analog_gain('B', 10)
cracker.osc_trigger_level(0)
cracker.osc_trigger_mode('E')
cracker.osc_trigger_edge('U')
cracker.uart_config(baudrate=serial.Baudrate.BAUDRATE_115200, bytesize=serial.Bytesize.EIGHTBITS, parity=serial.Parity.PARITY_NONE, stopbits=serial.Stopbits.STOPBITS_ONE)
time.sleep(2)
cmd = cmd_set_aes_enc_key + aes_key
cracker.uart_transmit_receive(cmd, timeout=1000, rx_count=6)
def do(cracker, count):
plaintext_data = random.randbytes(aes_data_len)
tx_data = bytes.fromhex(cmd_aes_enc.replace(' ', '')) + plaintext_data
status, ret = cracker.uart_transmit_receive(tx_data, rx_count= 6 + aes_data_len, is_trigger=True)
return {
"plaintext": plaintext_data,
"ciphertext": ret[-aes_data_len:],
"key": bytes.fromhex(aes_key)
}
def finish(c):
...
# print('optional behavior')
acq = cn.simple_acq(s1, init_func=init, do_func=do, finish_func=finish)
上面的代码中,定义了 init 和 do 两个方法(还有一个没有实现的 finish 方法,该方法可以用来在采集结束后执行一些操作,比如关闭Nut电源等 ),分别定义了初始化Cracker设备和向Cracker设备发送AES加密的数据两组操作。这组代码就实现了基础的AES加密能量数据的采集。
这里通过两个方法分别接收一个Cracker参数 ,供方法内部调用。
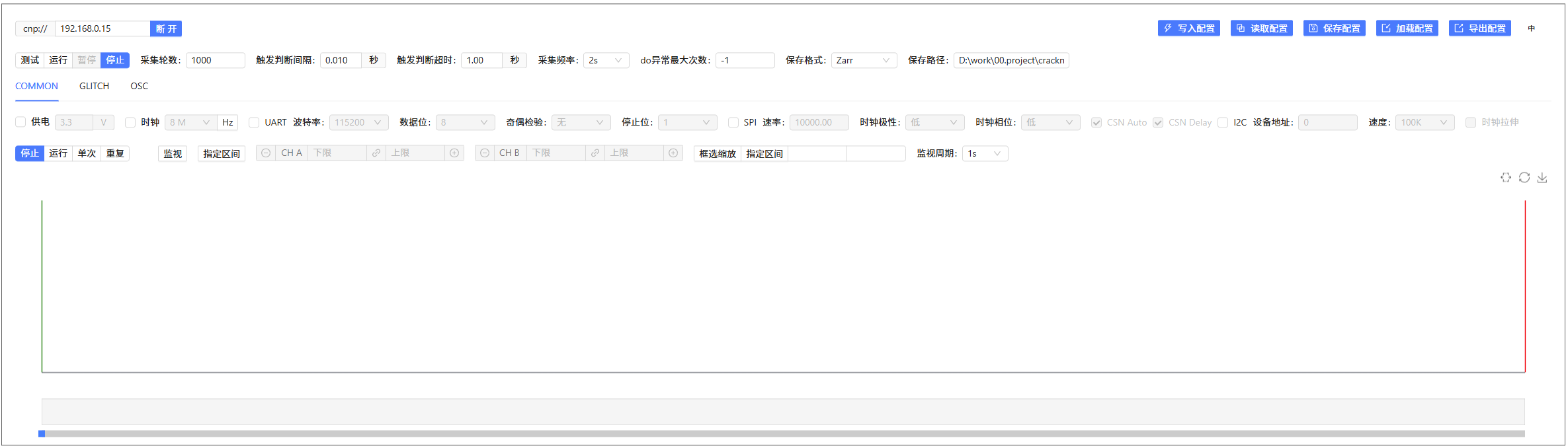
Cracker采集控制面板
插入如下代码并执行将显示Cracker采集控制面板界面,该界面集成Cracker设备控制、曲线采集流程控制、曲线监控于一体。
cn.show_panel(acq)
执行后展示效果如下:
能量曲线采集
在Cracker采集控制面板界面,点击连接后界面将展示设备的ID、名称、版本信息,并且激活下方的配置面板和波形监控面板。
点击测试按钮,即可对设备进行实时调试(监控波形,需要打开监控开关�),确保采集到正确的波形数据:
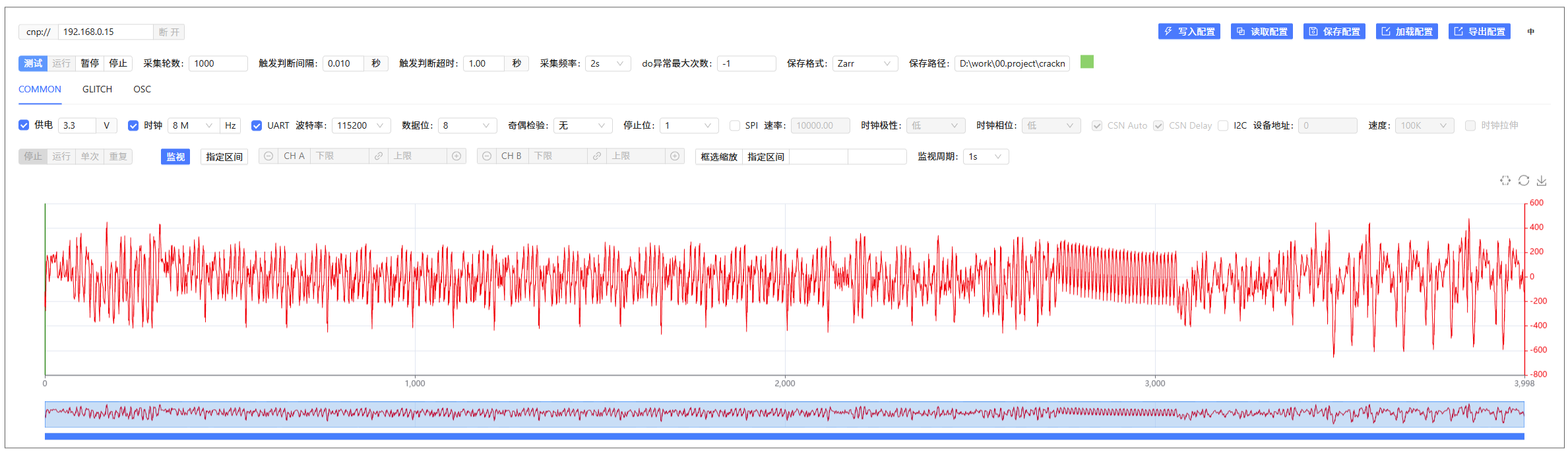
在调整到合适的参数后(在按照上述代码进行采集并使用NUT 103 golden 固件时,无需调整已是最好的效果),停止测试模式,点击运行按钮即可开始采集并保存波形数据:
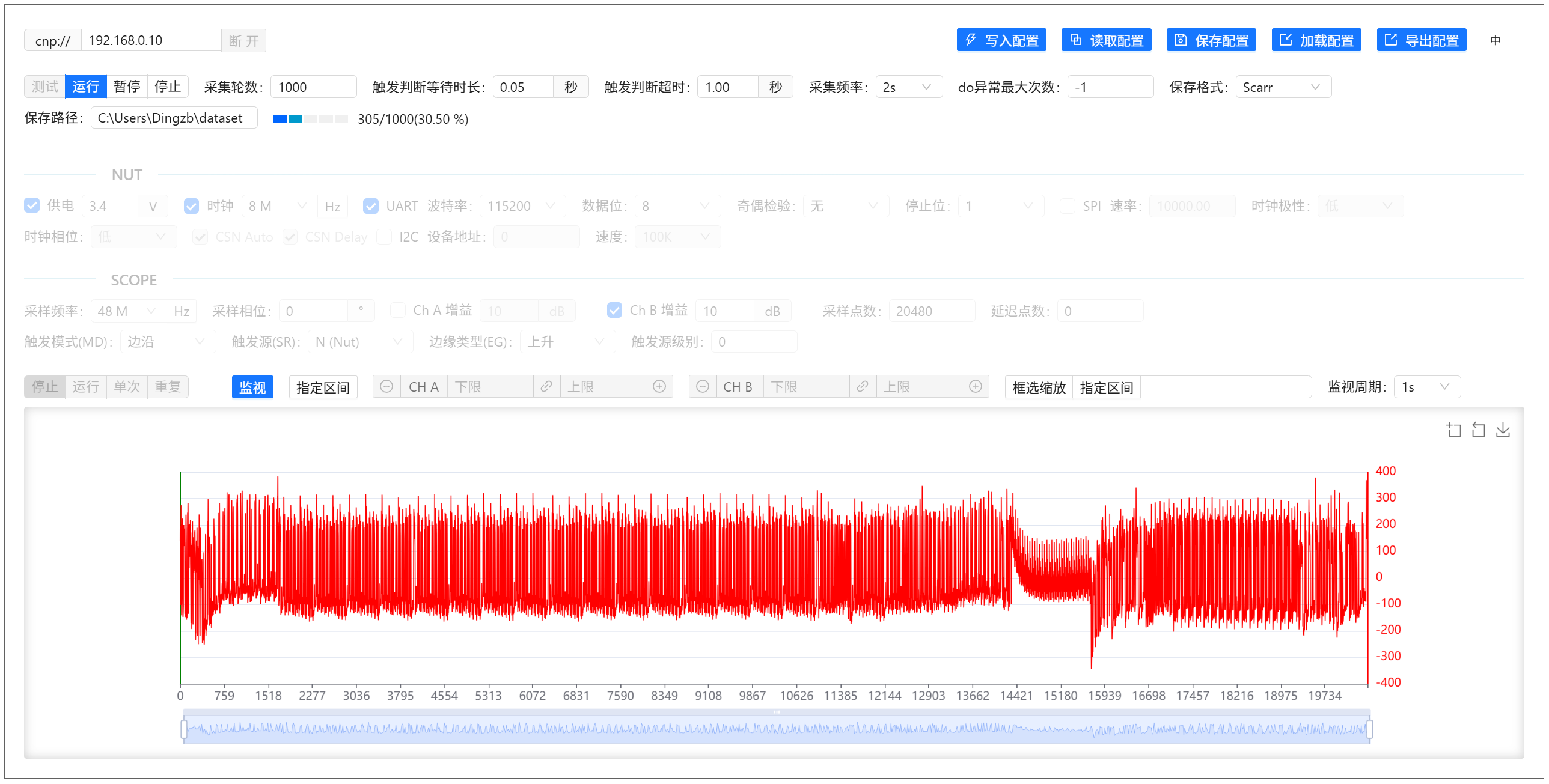
至此,恭喜您,您已经成功使用CrackNuts采集到了能量轨迹波形数据。
默认情况下随Cracker配套的 Nut(smt32_f103c8)已经烧录了HSI.elf固件,其他更多可用的固件可到https://pan.baidu.com/s/1PXyKqeTfemepZ-wD9gDwYQ?pwd=2cda的 NutGolden 文件夹进行下载。
能量曲线使用
采集到的能量曲线数据存储格式默认为 zarr 格式,并且规定了数据的存储路径,具体如下:
MyData.zarr/ <-- [根目录]
│
├── origin/ (或者 "0") <-- [一级分组] 数据集类型 (兼容旧名 "0")
│ │
│ ├── 0/ <-- [二级分组] 通道 0
│ │ ├── trace [Array] (该通道的波形数据)
│ │ ├── plaintext [Array]
│ │ ├── ciphertext [Array]
│ │ ├── key [Array]
│ │ └── ... [Array]
│ │
│ └── 1/ <-- [二级分组] 通道 1 (如果有双通道采集)
│ ├── trace [Array]
│ ├── plaintext [Array]
│ ├── ciphertext [Array]
│ ├── key [Array]
│ └── ...
│
├── aligned/ <-- [一级分组] 处理后的数据集
│ │
│ ├── 0/ <-- [二级分组] 对应通道 0 的对齐数据
│ │ ├── trace [Array] (对齐后的波形)
│ │ └── ...
│ │
│ └── 1/
│ └── ...
├── ...
└── attrs
数据集的根据路下分为多个分组,
其中默认存在的分组为origin分组,他是采集到的原始功耗或电磁数据,其下的每个二级分组对应一个通道,每个通道下包含 trace、plaintext、ciphertext、key 四个数据集,分别对应采集到的波形数据、明文数据、密文数据和密钥数据。
另外存在的诸如aligned分组,是处理后的数据集,其下每个二级分组对应一个通道,每个通道下至少包含 trace 数据集,其他数据集暂未定义。
目前版本,仅支持 origin 分组,其他分组在分析框架完善后陆续添加。
采集到的能量曲线数据默认存储在Jupyter notebook的同级目录的dataset目录下,以时间戳命名,可以使用如下方式加载已经保存到本地的曲线文件
-
使用
CrackNuts的TraceDataSet:ds = cn.load_trace_dataset('./dataset/20260123151941.zarr/')
ds.info() # 查看数据集信息ds.plot() # 显示曲线查看面板 -
直接使用
zarr打开import zarr
zd = zarr.open('./dataset/20260123151941.zarr/')
zd.tree()可以看到数据的格式如下:
