上位机使用指南
上位机使用Python语言开发,通过TCP协议与设备进行通信。
推荐在Jupyter环境下使用上位机对设备进行操作,这样可以利用上位机提供的设备控制面板减少代码编辑量,并且能够通过示波器面板实时查看到设备参数配置的效果。
上位机总体架构如下图:
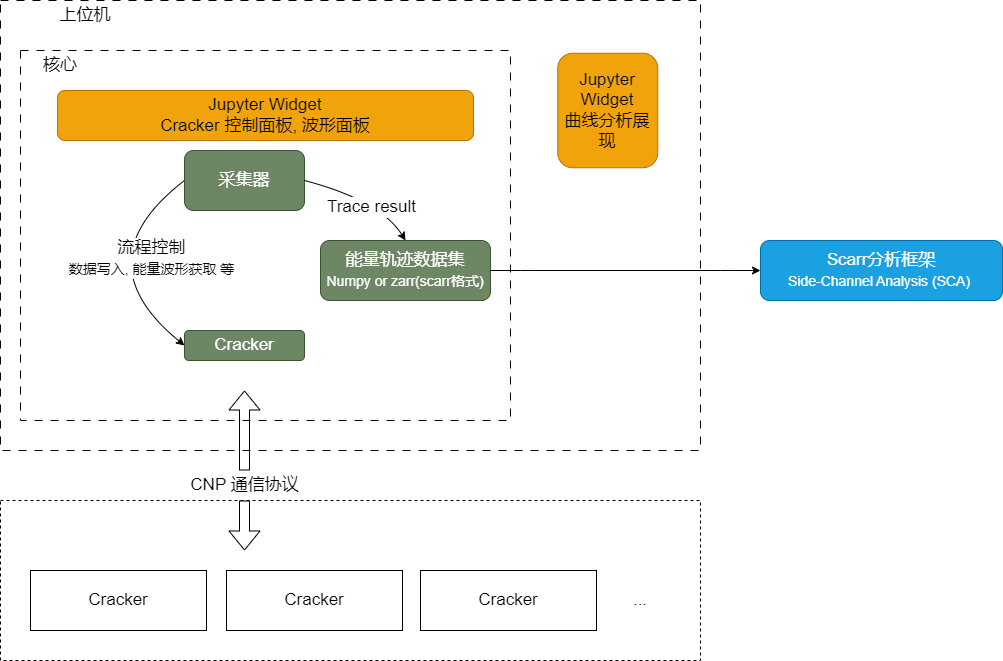
对于上位机SDK的API说明,可访问https://cracknuts.readthedocs.io/zh-cn/stable/了解。
上位机中Cracker代表设备,Acquisition代表采集流程,围绕这两个模块上位机可以实现对设备的控制、数据的采集。
命令行工具
安装完CrackNuts后,在控制台中提供cracknuts命令,提供以下Jupyter快捷命令:
- 启动
Jupyter labcracknuts lab - 打开教程
cracknuts tutorials - 创建新笔记文件
cracknuts create -t [template name] -n [new notebook name] - 全局配置
cracknuts config set lab.workspace # 配置 cracknuts lab 打开的默认工作目录
上位机基本使用
上位机安装成功后,可以通过Python对设备进行控制。如下,通过Python控制台直接访问设备并进行配置:
-
启动
Python环境:
通过快速安装方式安装的CrackNuts,可以通过快捷图标启动CrackNuts环境,其他方式安装的可以根据自己的情况选择合适的方式进入有CrackNuts依赖的Python环境
-
连接设备并对Nut配置电压
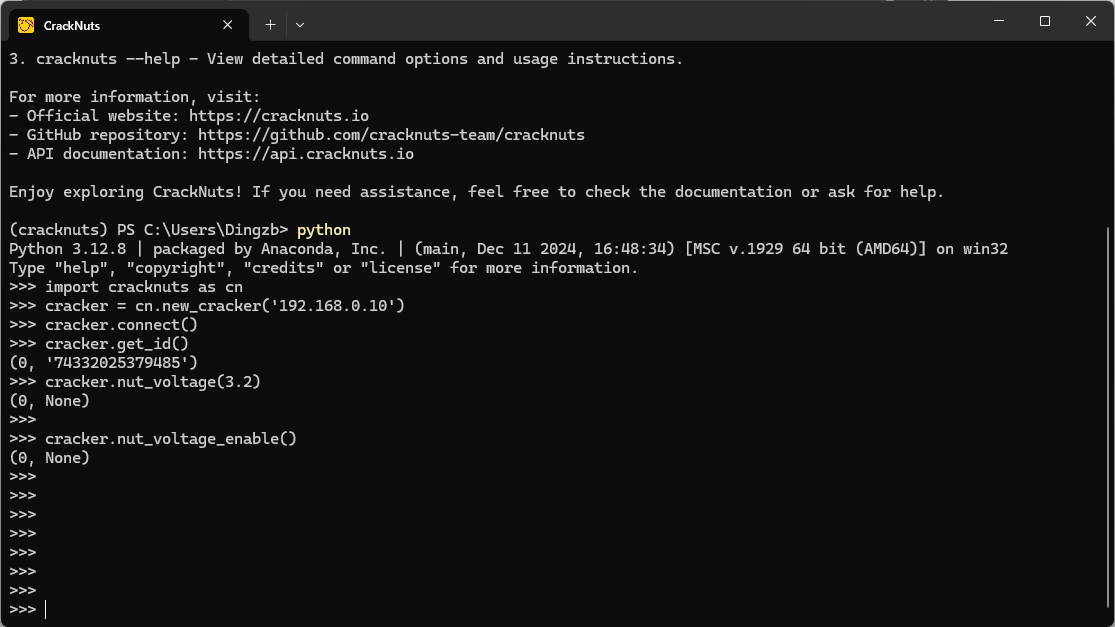
以上代码解释如下:
# 引入 cracknuts
>>> import cracknuts as cn
# 通过快速入口函数创建一个Cracker对象
>>> cracker = cn.new_cracker('192.168.0.211')
# 连接设备
>>> cracker.connect()
# 获取设备ID,此处仅用于验证连接状态,这是一个验证设备正确连接的简单有效方法
>>> cracker.get_id()
(0, '74332025379485') # 此处为 CrackNuts 上位机 API 的返回格式:元组第一位为函数执行状态位,0 表示成功,其他表示失败; 第二位位返回数据位,此处获取设备ID(S/N)即在此处,对于没有返回数据需求的接口则为None
# 配置Nut设备电压为3.2V
>>> cracker.nut_voltage(3.2)
(0, None)
# 对Nut进行使能操作,此时默认的stm32 103的Nut板上应该亮灯
>>> cracker.nut_voltage_enable()
(0, None)
>>>以上就完成了最简单的上位机的控制,其他更丰富的配置可阅读API文档了解。
采集流程
在“快速开始”章节中,您可能已经注意到,使用 CrackNuts 进行波形采集时,仅需控制 Nut 的动作,即可完成能量波形的采集。这是因为 CrackNuts 设计了一套简化的采集流程,旨在降低操作复杂度,使用户能够专注于 Nut 的加密等核心流程控制。
该采集流程由 Acquisition 类负责管理,即使用控制面板前创建的 acq 对象。该对象实现了指令发送、加密数据保存、能量轨迹保存等关键步骤,并预留了 init 和 do 两个阶段,供用户插入自定义逻辑。通过该流程,用户可以实现以下功能:
- 使用图形界面配置参数,支持波形实时展示,便于调整设备设置;
- 自动保存配置参数,方便实验流程复现;
- 自动保存采集到的曲线数据,便于后续的数据分析。
采集流程的结构如下图所示:

与这个流程对应的Cracker及Nut的流程图如下图:

图中,CrackNuts 表示上位机软件,Cracker 是测试设备,Nut 为被测对象,下发的 Wave 则代表侧信道信号。
用户需实现两个函数:init() 和 do(),其中 init() 函数仅在采集流程开始时执行一次,而 do() 函数则会被循环调用。
在这两个函数中,用户可编写具体的指令逻辑,通过 Cracker 下发给 Nut,并接收 Nut 返回的数据,由 Cracker 再转发回 CrackNuts 上位机程序。
当 init() 函数执行完成后,CrackNuts 会自动向 Cracker 下发 osc_single() 命令,将其设置为“准备采集曲线”模式。具体的触发条件可通过上位机界面或命令进行配置,支持的参数包括:信号源(A/B 通道)、触发对象(如 Nut)、通信协议等。
在 do() 函数执行期间,Cracker 会实时检测触发条件,一旦条件满足,即刻采集波形数据。
待 do() 函数执行完毕后,CrackNuts 会自动判断是否成功触发采集:如触发成功,则从 Cracker 中读取采集到的数据并进行保存。
在快速开始章节中的创建Acquisition,就是这个采集流程:
import random
import time
from cracknuts.cracker import serial
cmd_set_aes_enc_key = "01 00 00 00 00 00 00 10"
cmd_aes_enc = "01 02 00 00 00 00 00 10"
aes_key = "11 22 33 44 55 66 77 88 99 00 aa bb cc dd ee ff"
aes_data_len = 16
sample_length = 1024 * 20
def init(c):
cracker.nut_voltage_enable()
cracker.nut_voltage(3.4)
cracker.nut_clock_enable()
cracker.nut_clock_freq('8M')
cracker.uart_enable()
cracker.osc_sample_clock('48m')
cracker.osc_sample_length(sample_length)
cracker.osc_trigger_source('N')
cracker.osc_analog_gain('B', 10)
cracker.osc_trigger_level(0)
cracker.osc_trigger_mode('E')
cracker.osc_trigger_edge('U')
cracker.uart_config(baudrate=serial.Baudrate.BAUDRATE_115200, bytesize=serial.Bytesize.EIGHTBITS, parity=serial.Parity.PARITY_NONE, stopbits=serial.Stopbits.STOPBITS_ONE)
time.sleep(2)
cmd = cmd_set_aes_enc_key + aes_key
status, ret = cracker.uart_transmit_receive(cmd, timeout=1000, rx_count=6)
def do(c):
plaintext_data = random.randbytes(aes_data_len)
tx_data = bytes.fromhex(cmd_aes_enc.replace(' ', '')) + plaintext_data
status, ret = cracker.uart_transmit_receive(tx_data, rx_count= 6 + aes_data_len, is_trigger=True)
return {
"plaintext": plaintext_data,
"ciphertext": ret[-aes_data_len:],
"key": bytes.fromhex(aes_key)
}
acq = cn.new_acquisition(cracker, do=do, init=init)
这其中new_acquisition必须传入的参数中含义如下,其他更:
- cracker: Acquisiton 流程要管理的
Cracker目标 - do: 用户具体的加密逻辑函数,并且回需返回要保存到波形文件中的数据
- init: 能量轨迹采集开始前的准备工作,如一些基础的配置
同样的,在控制面板中(关于控制面板的介绍在后续在Jupyter中使用CrackNuts上位机中有介绍),有着更丰富的流程控制参数可以配置:
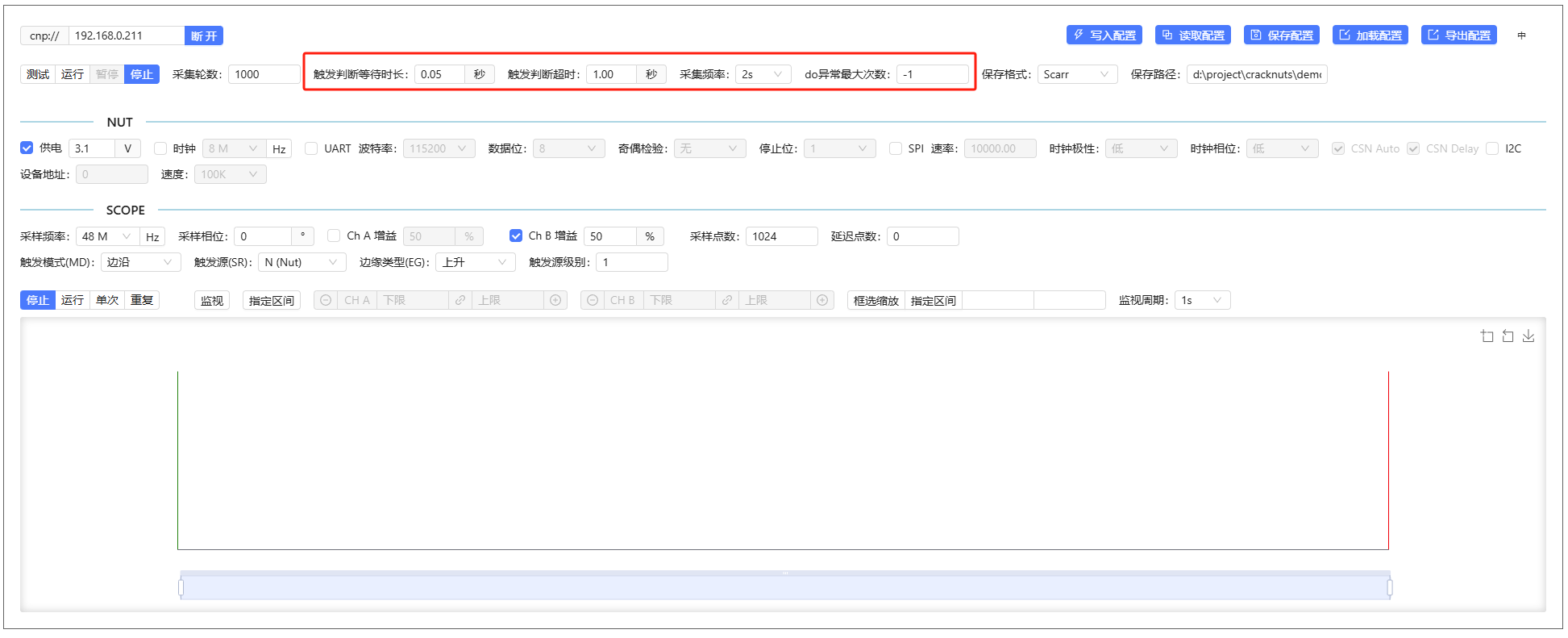
其含义如下(参考上面的流程图可更好的理解)这些参数如果对整体流程不了解的情况下不建议修改:
- 触发判断等待时长:每次
is_trigger判断之间的间隔 - 触发判断超时:经过该时常后设备依然没有判定到触发状态,则认为该轮采集失败
- 采集频率:在测试模式下每隔多长时间对设备进行一次加密数据操作
- do异常最大次数:用户do函数中的代码允许出现错误的次数,默认-1不允许出现错误
除了上面的流程控制参数外,控制面板的流程管理区域其他功能如下:
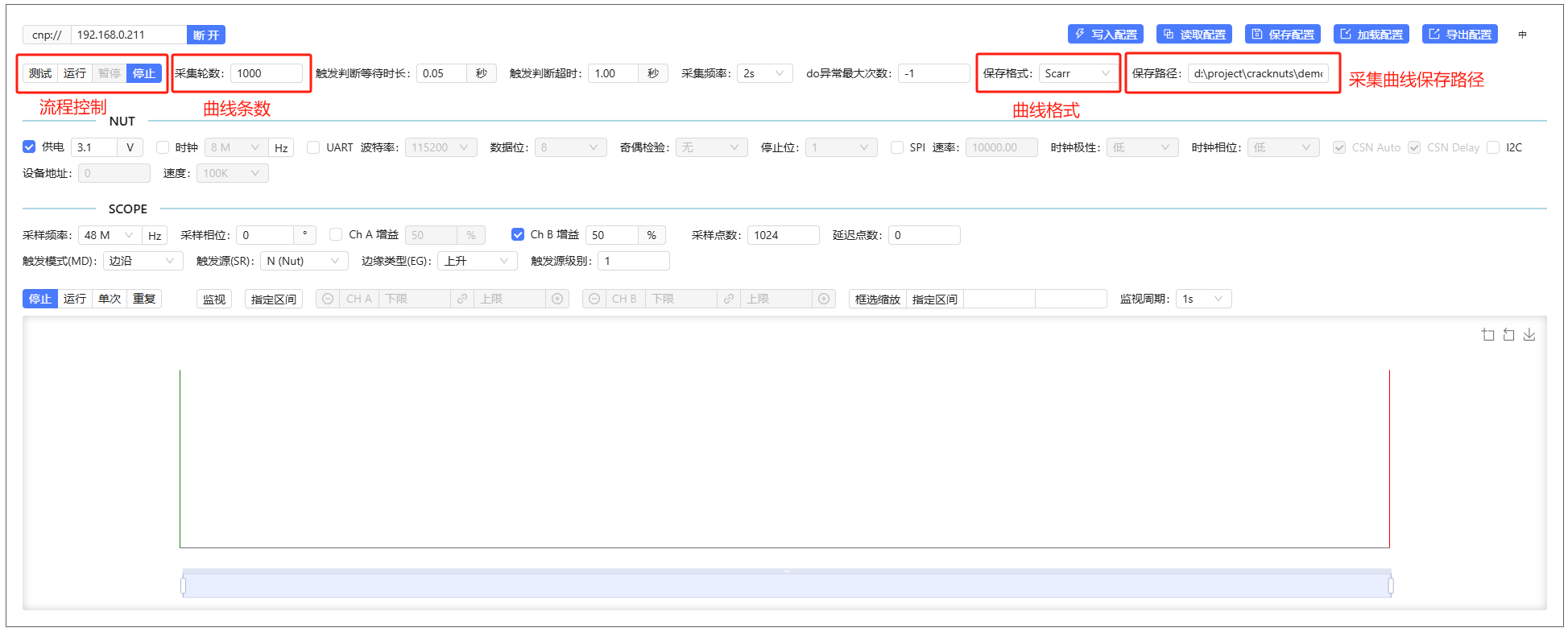
- 流程状态控制:
- 测试:仅进行数据加密、能量轨迹操作不保存波形文件
- 运行:进行完整的数据加密、能量采集、文件保存操作
- 暂停:暂停当前的测试或运行流程
- 停止:停止当前的测试或运行流程
- 采集轮数:采集的曲线数量,即执行多少次do函数的内容
- 保存格式:曲线文件的保存格式,默认是
scarr格式,可选numpy格式 - 保存路径:曲线文件的保存文件夹,曲线文件会以时间戳格式命名保存到这个目录下
CrackNuts面板的其他功能可参考后续章节的介绍。
在Jupyter中使用CrackNuts上位机
除了可以在Python控制台和Python脚本文件中使用CrackNuts外,还可以使用Jupyter环境,也是我们推荐的方式。在Jupyter中我们提供了更为简洁的GUI控制面板方式实现对设备的控制、数据的展现。
并且还提供了cracknuts lab这个简洁命令来启动一个Jupyter环境。
通过以上命令可以启动一个Jupyter lab 环境,之后就可以创建一个Jupyter Notebook来开始控制设备

在新建的Notebook中分两个单元格输入如下内容,即可打开设备控制面板:
import cracknuts as cn
cracker = cn.new_cracker('192.168.0.10')
cracker.connect()
cracker.get_id()
cracker.nut_voltage(3.1)
cracker.nut_voltage_enable()
每一个单元格填写完成代码后,执行代码即可完成代码的执行,效果如下图。(可以使用Ctrl+Enter来执行,也可使用Shift+Ctrl执行,后者执行完成后下一个单元将自动激活)
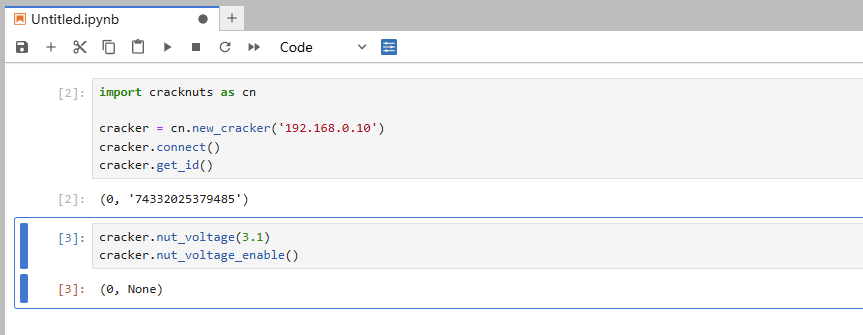
按照以上步骤执行后,可以同样完成对Nut的电压配置和使能配置。
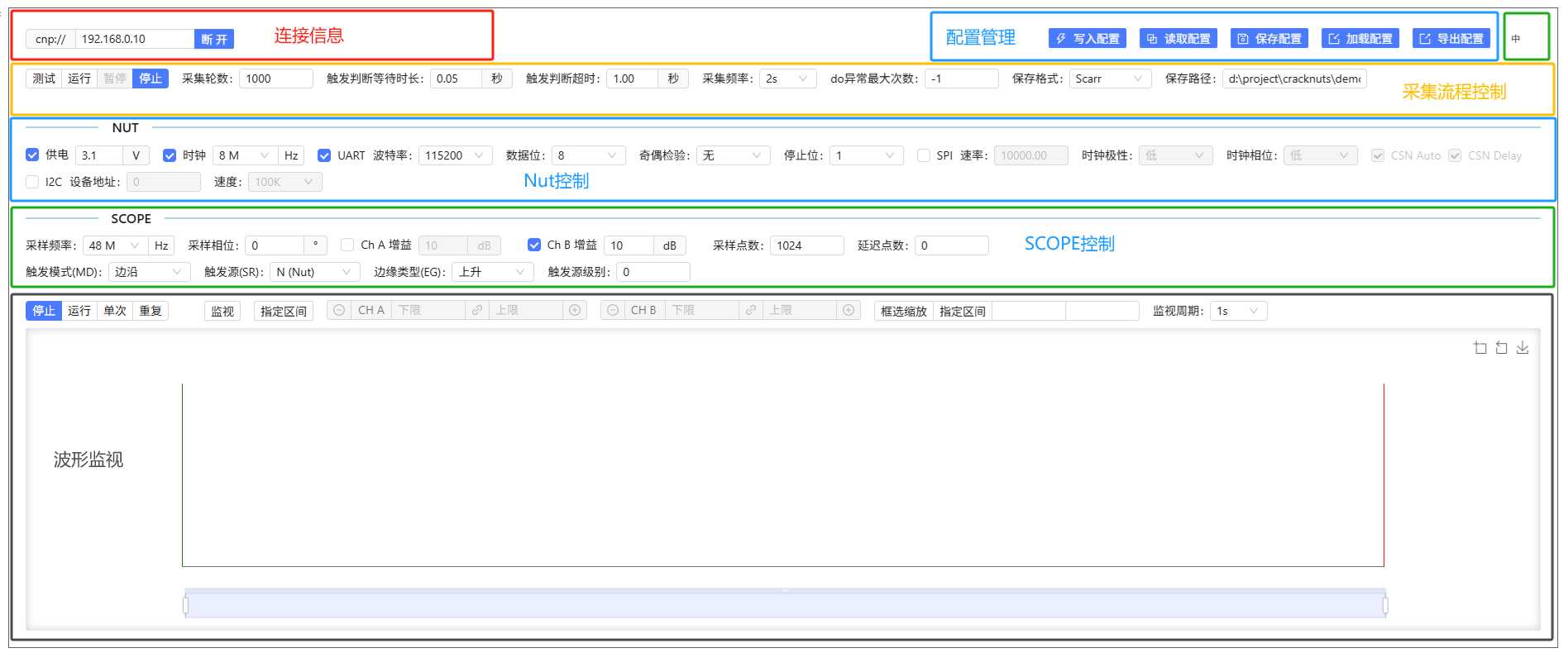
Jupyter控制面板组件
在Jupyter中还可以使用设备控制面板对设备进行控制,执行如下代码开启设备控制面板
# 创建一个空采集流程控制对象,
acq = cn.new_acquisition(cracker)
# 展示面板
cn.panel(acq)
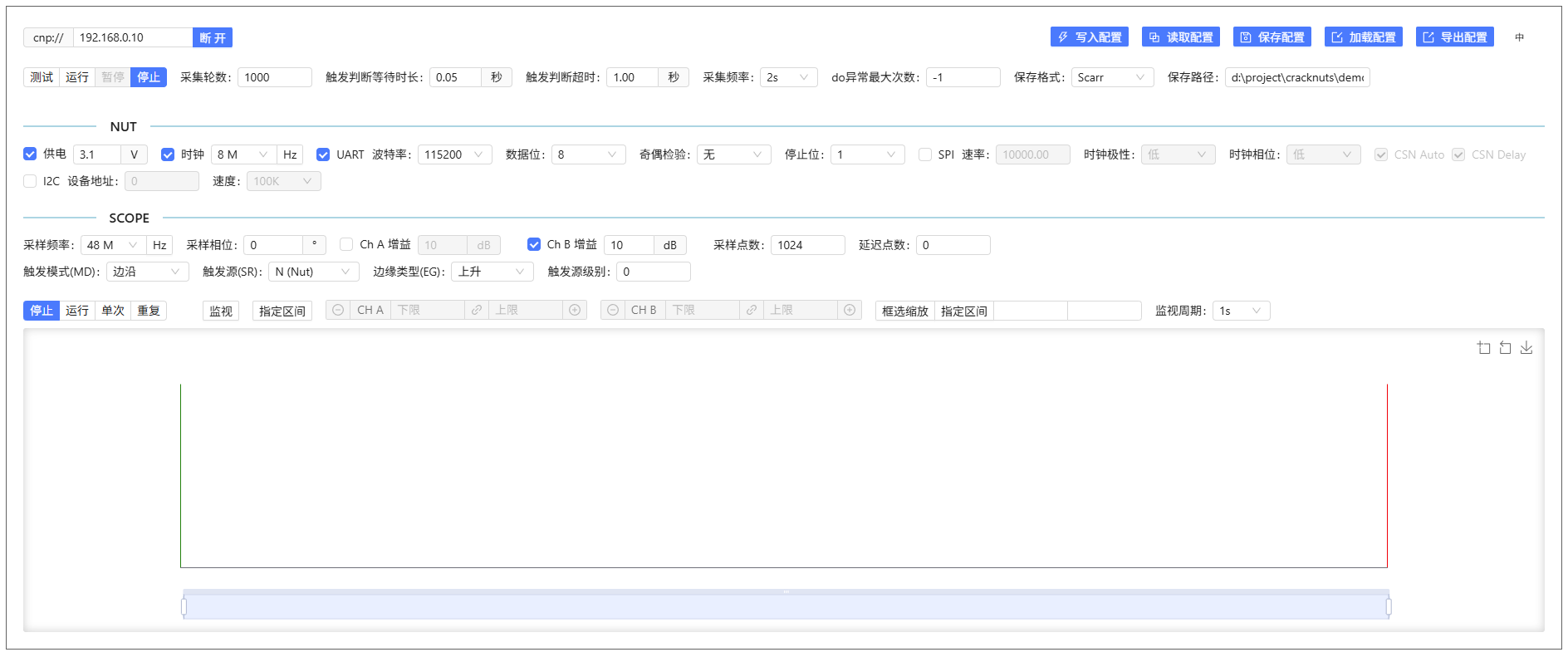
设备控制面板集成了采集流程管理、NUT管理、SCOPE管理、模型展现四个大功能模块,分别实现能量轨迹的采集管理、NUT目标板控制、Cracker采集板控制、波形展现这四类功能。
波形展示
CrackNuts上位机提供了用于展示采集到的波形的jupyter控件,他可以高效的对波形进行缩放等操作。
如下可以打开一个CrackNuts采集到的波形数据集:
import cracknuts as cn
from cracknuts.trace import ZarrTraceDataset
trace_path = r'./dataset/20250519122059.zarr'
# 加载 scarr 格式的数据集
ds = ZarrTraceDataset.load(trace_path)
pt = cn.panel_trace()
pt.set_trace_dataset(ds)
pt
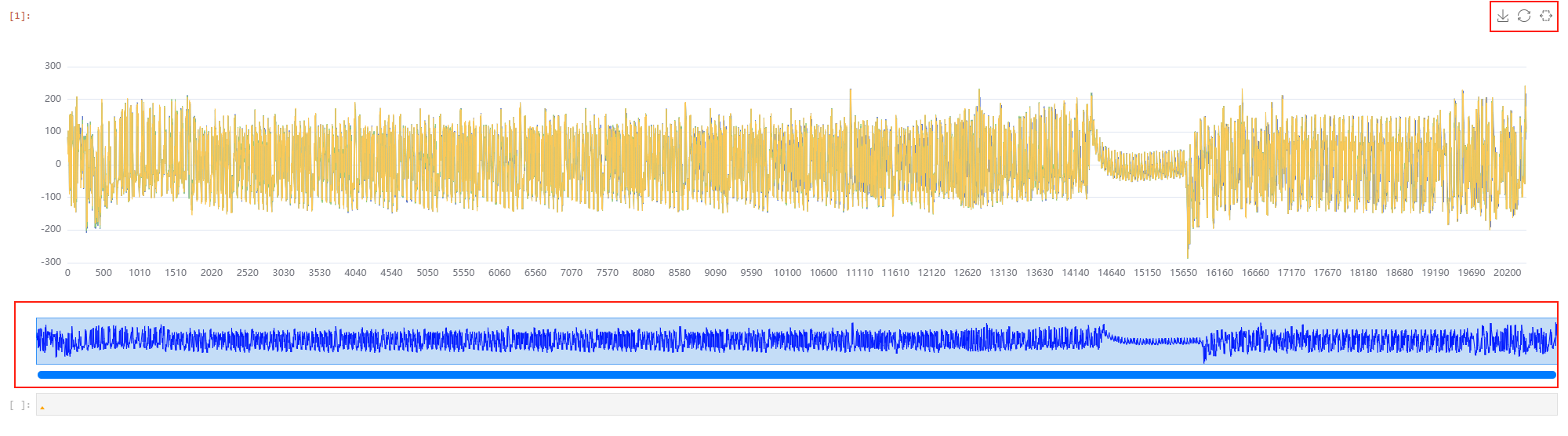
在上图中,有上角的控制区域分别可以下载、重置缩放、开启选择缩放,在下方的缩放指示区域可以显示当前缩放的区间以及进行缩放区间的拖动
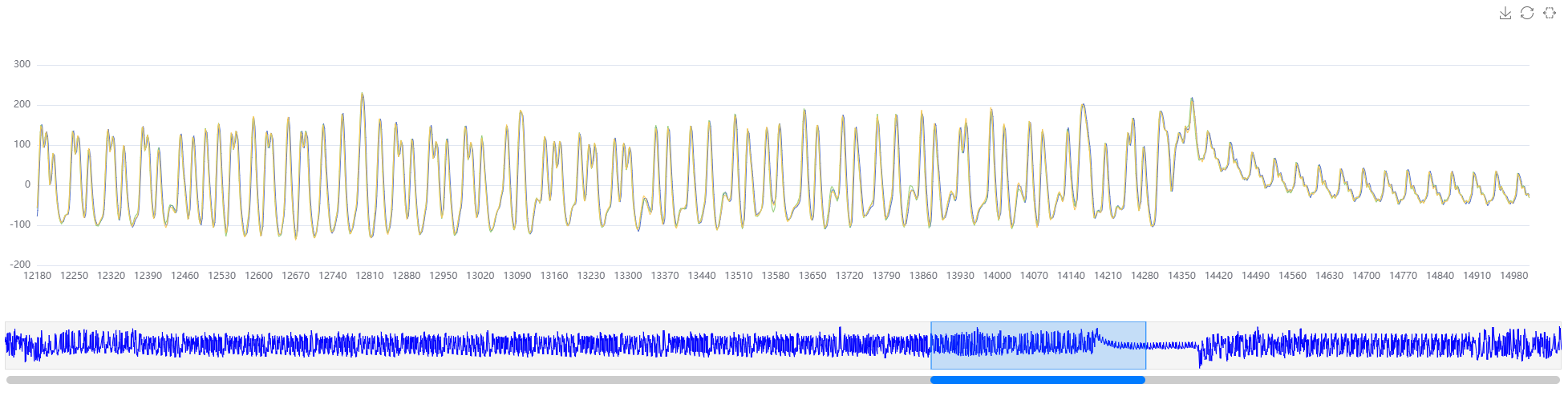
鼠标在波形上点击后可显示当前位置的坐标及数值信息
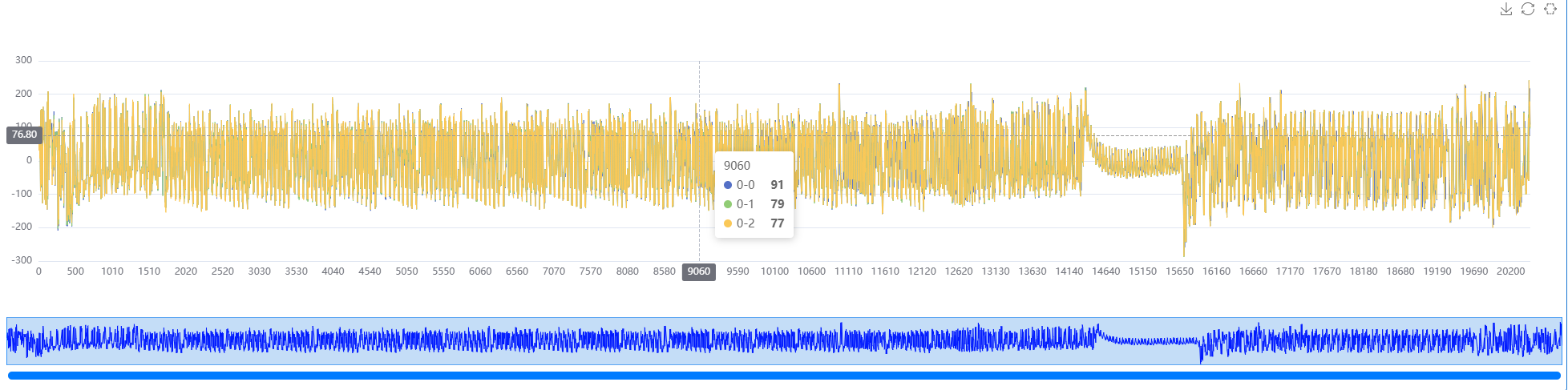
除了在这个Jupyter组件中以鼠标进行缩放控制,还可以通过代码进行精确控制
# 通过索引指定缩放的区间
pt.change_range(100, 1000)
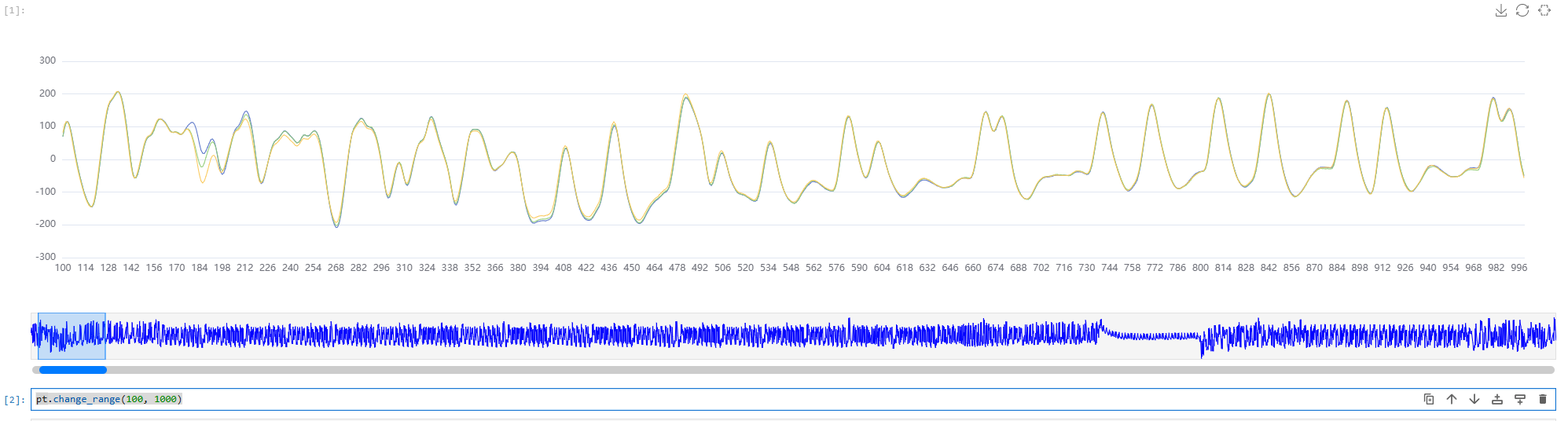
# 通过比例指定缩放的区间
pt.change_percent_range(10, 20)
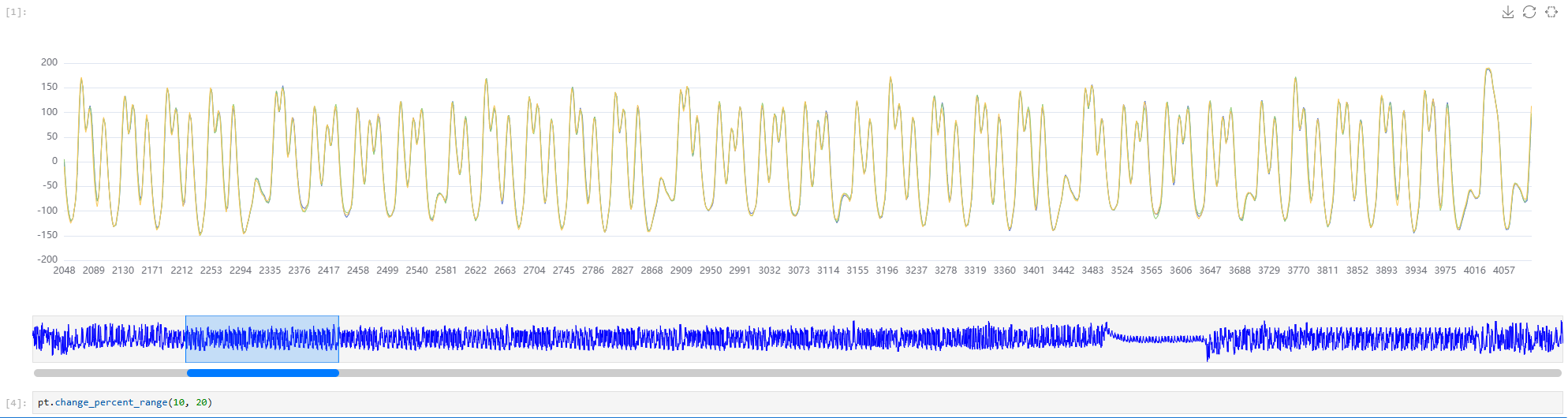
此外由于采集的数据点一般来说会比较大,为了快速展示波形默认展示前三条曲线,当需要切换曲线时,可以通过show_trace属性进行控制。
show_trace是一个TracePanelWidget的属性,他可以进行切片操作,第一个切片是通道索引、第二个是曲线索引。
pt.show_trace[0, :10] # 通道0的前10条
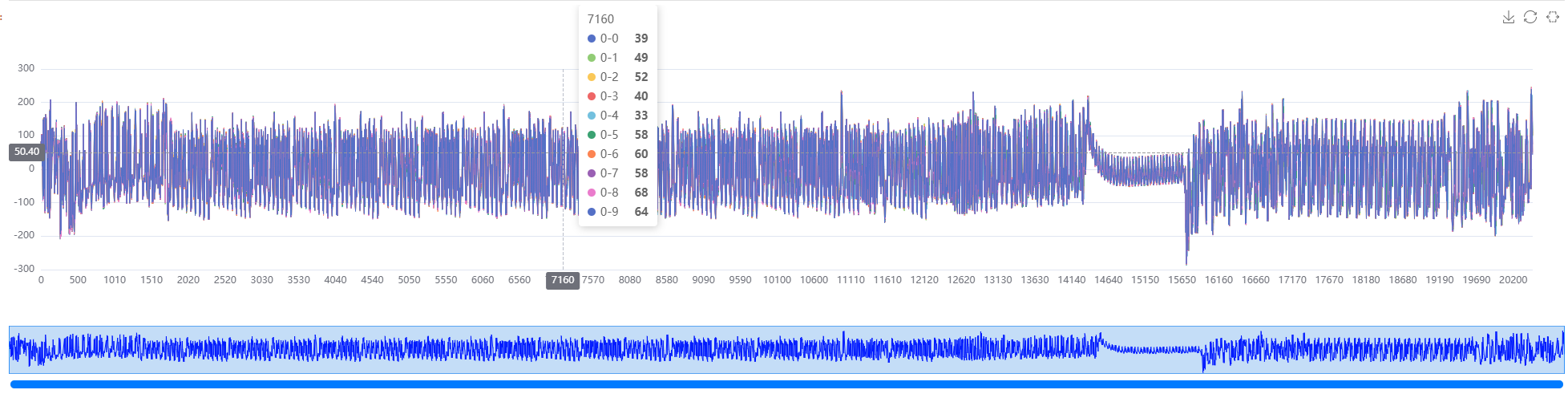
pt.show_trace[0, 1:10:2] # 通道0的1到10,步长为2
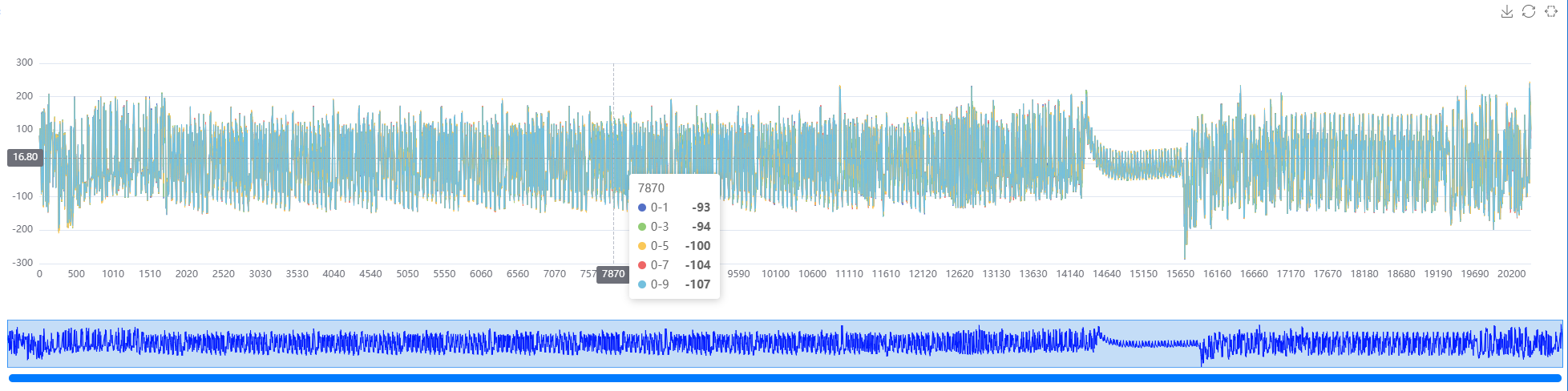
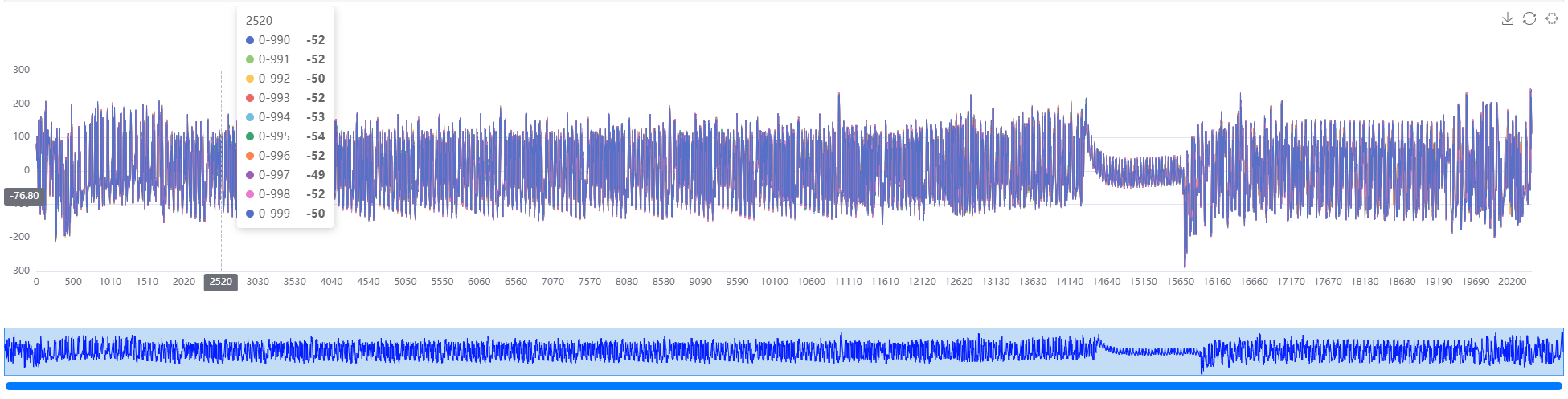
pt.show_trace[0, -10:] # 后10条
除了能够打开CrackNuts采集的数据集文件外,他还可以直接打开numpy数组以方便查看分析中间过程。数组需要是一个一维或二维数组,二维数组时第一个维度为曲线、第二维度为曲线的数据点,如下:
import numpy as np
y = np.random.randint(100, size=(10, 1000)) # 生成一个二维数组
pt.set_numpy_data(y)
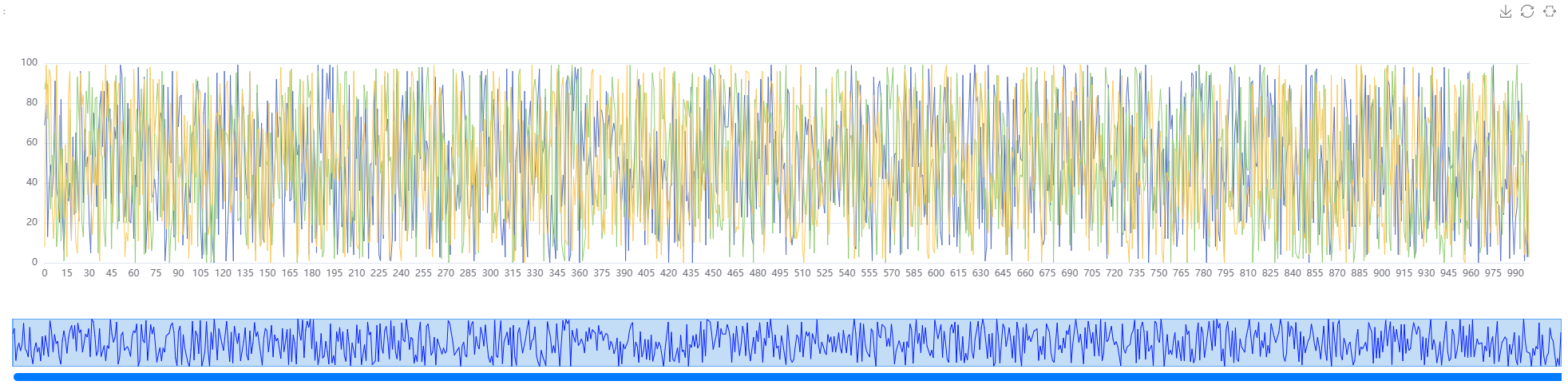
以上是一个随机数的numpy例子,更多的情况是在曲线分析后,可以查看相关性
# 详细曲线分析过程略,参考快速开始章节
from scarr.engines.cpa import CPA as cpa
from scarr.file_handling.trace_handler import TraceHandler as th
from scarr.model_values.sbox_weight import SboxWeight
from scarr.container.container import Container, ContainerOptions
import numpy as np
handler = th(fileName=trace_path)
model = SboxWeight()
engine = cpa(model)
container = Container(options=ContainerOptions(engine=engine, handler=handler), model_positions = [x for x in range(16)])
container.run()
result_bytes = np.squeeze(container.engine.get_result())
correlation_best = result_bytes[0, 0x11, :5000] # 第0位的第0x11个猜测密钥的相关型
pt.set_numpy_data(correlation_best)
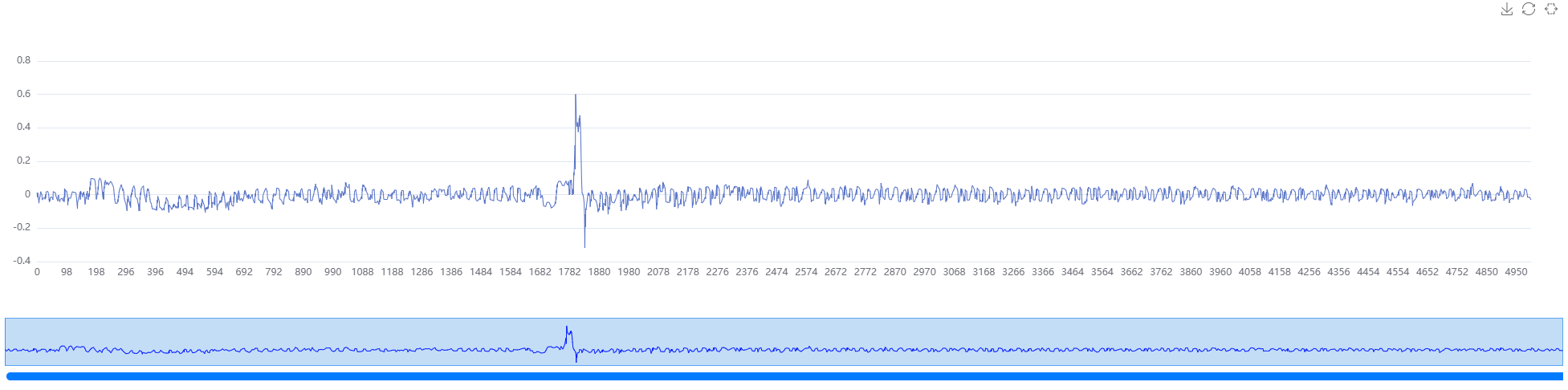
当然也可以查看相关性矩阵的全部数据并高亮猜测出的密钥那条曲线(但不建议这样做,因为我们的组件是具有交互性质的,由于相关性矩阵数据很大会造成页面卡顿,可参考快速开始使用静态展示的方式查看)
correlation = result_bytes[0, :, :5000] # 获取第0位的所有猜测密钥相关性曲线
pt.set_numpy_data(correlation)
pt.show_all_trace() # 展示全部曲线
pt.highlight(0x11) # 高亮
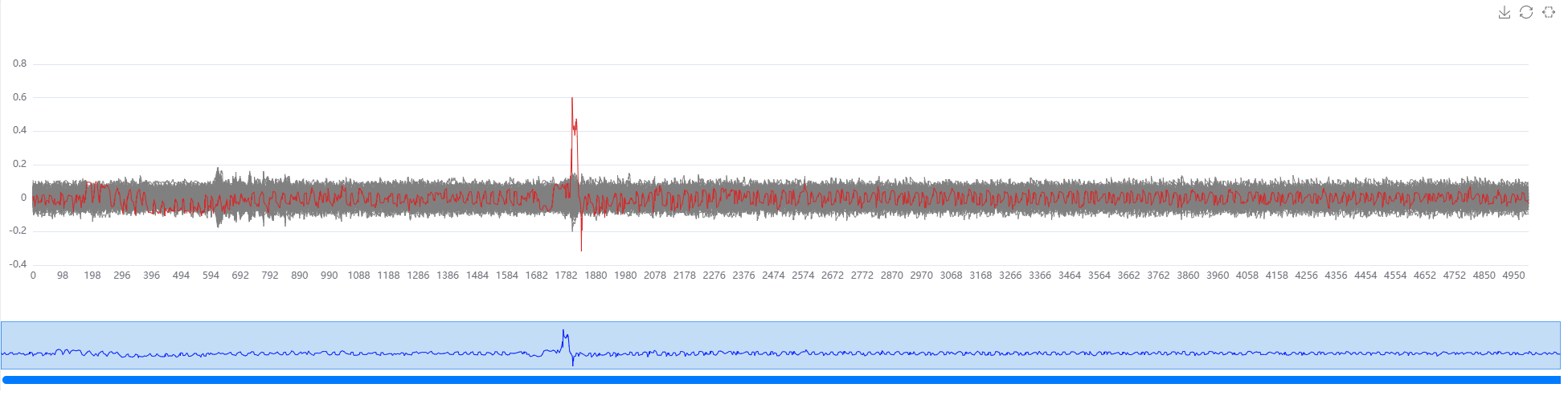
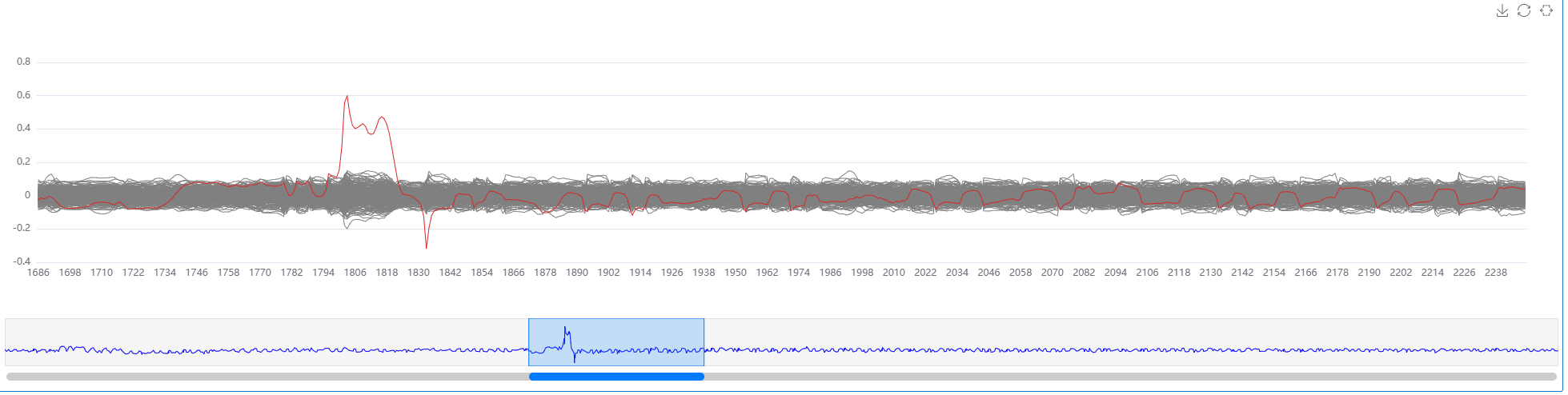
相关性(分析结果)
如果您使用cracknuts-squirrel库进行了相关性、CPA等分析,他可以产生一个最终的相关性矩阵,该数据同样采用zarr作为存储格式,其格式如下:
-
correlation:
- directory.zarr/X/Y/correlation
-
/X/Y固定为/0/0 -
correlation 中存储的是一个 三维数组,
- 当计算相关性时,第一个维度为 计算相关性的明文或密文的索引,第二个维度为 曲线数据点索引,第三个为 相关性曲线数据
- 当CPA分析时,第一个维度为猜测密钥的索引,第二个为密钥的比特位索引,第三个为 相关性曲线数据
其格式与采集数据略有不同,在使用上,将数据的第一个维度代替 能量轨迹 的 通道维度,一次来使用。
更多详细内容,请参考 squirrel 文档。
import cracknuts as cn
pt = cn.panel_trace()
pt.set_trace(r'D:\project\cracknuts\demo\jupyter\dataset\20250521110621(aes)_CPAAnalysis.zarr')
pt
如上代码就打开一个squirrel分析结果,该结果是一个CPA分析结果。
如下面,可以指定查看曲线:
pt.show_trace[0x22, 1] # 显示一条曲线,第 0x22 这个猜测密钥的 第 1 个字节的相关性曲线(该曲线包含相关性的峰值部分)
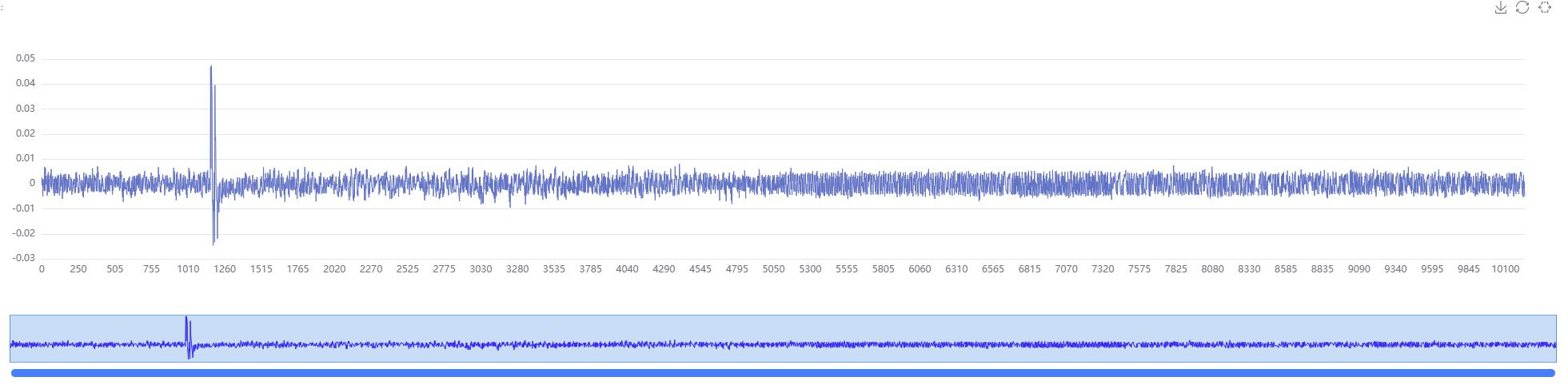
高亮一条曲线:
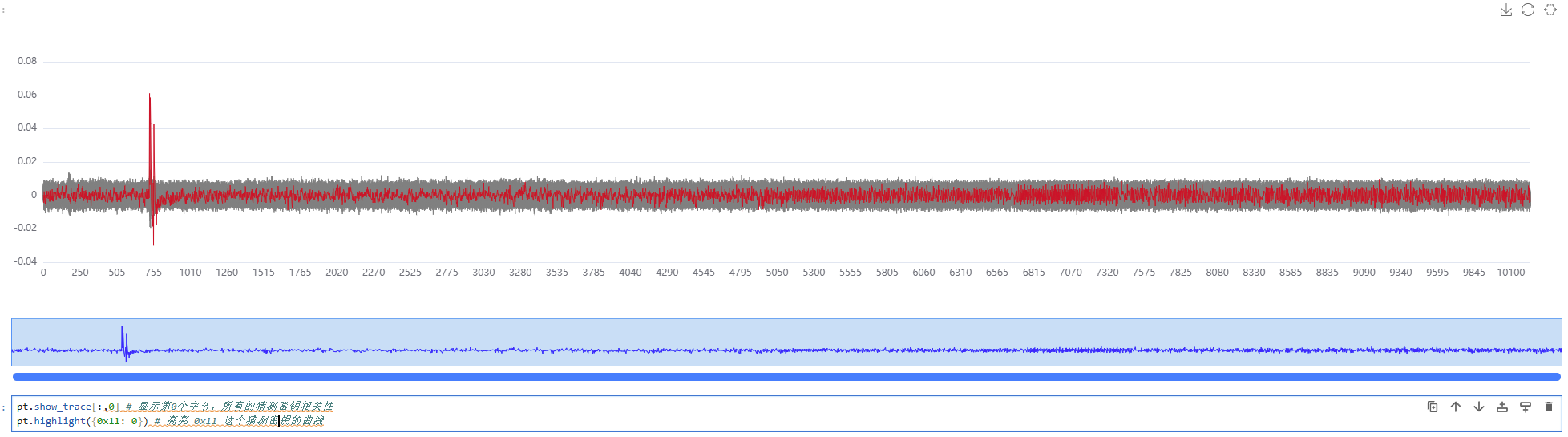
pt.show_trace[:,0] # 显示第0个字节,所有的猜测密钥相关性
pt.highlight({0x11: 0}) # 高亮 0x11 这个猜测密钥的曲线
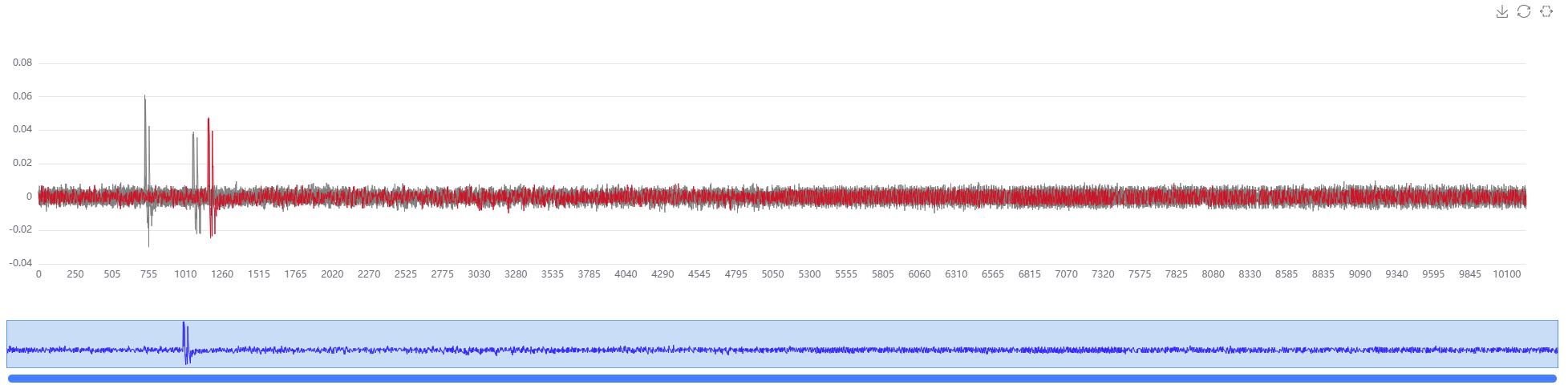
pt.show_trace[[0x11, 0x22, 0x33], [0,1,2]] # 展示多个相关性波峰
pt.highlight({0x22: 1}) # 高亮 0x22 这个猜测密钥的曲线
Jupyter Notebook 配置
在Jupyter中使用控制面板后,可以使用配置功能,该功能可以将当前面�板中的配置进行保存、导出、导入、写入设备操作,也可以读取设备的当前配置到面板。
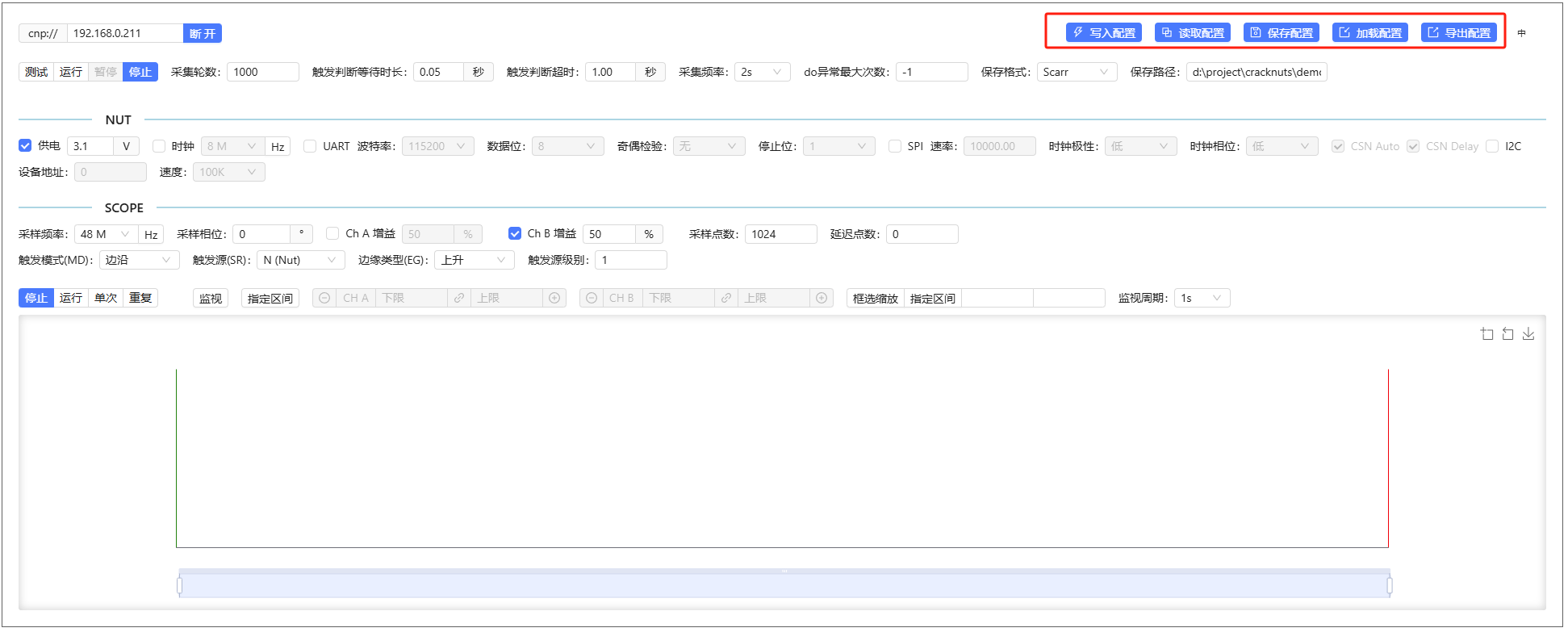
保存配置与导出配置的区别是,其把当前配置保存到与Jupyter Notebook文件关联的配置文件中,下次打开该Jupyter Notebook中的设备控制面板时自动加载该配置。、
而导出配置则导出到一个配置文件,用户可以在需要的时候通过加载配置加载该配置。
默认情况下,通过代码对Cracker的配置会同步到控制面板中,但是如果控制面中加载了配置文件中配置(无论是加载的关联Jupyter Notebook还是通过加载配置配置加载的外部配置)
并且其与设备中的配置不一致,控制面板将通过写入配置这个按钮变成红色进行提示,此时通过代码对设备的配置将不同步到控制面板中,直到通过写入按钮把配置写入到设备。
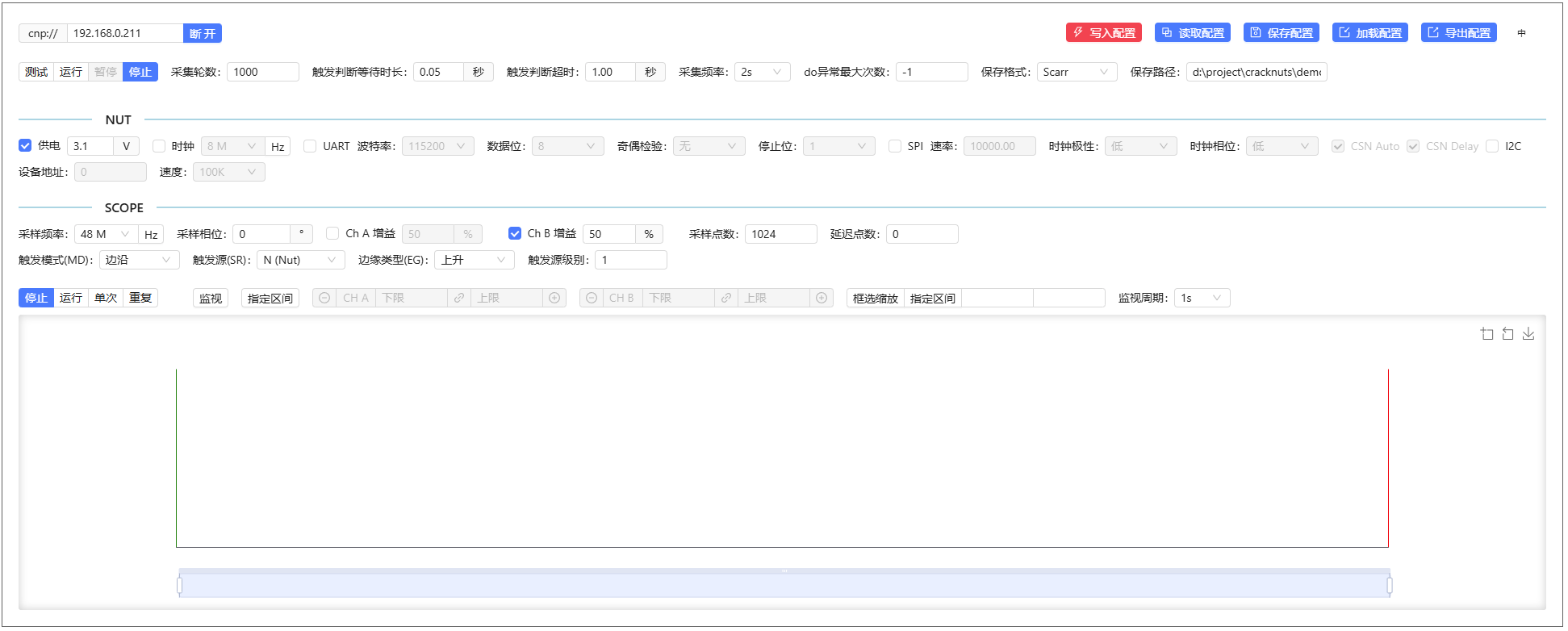
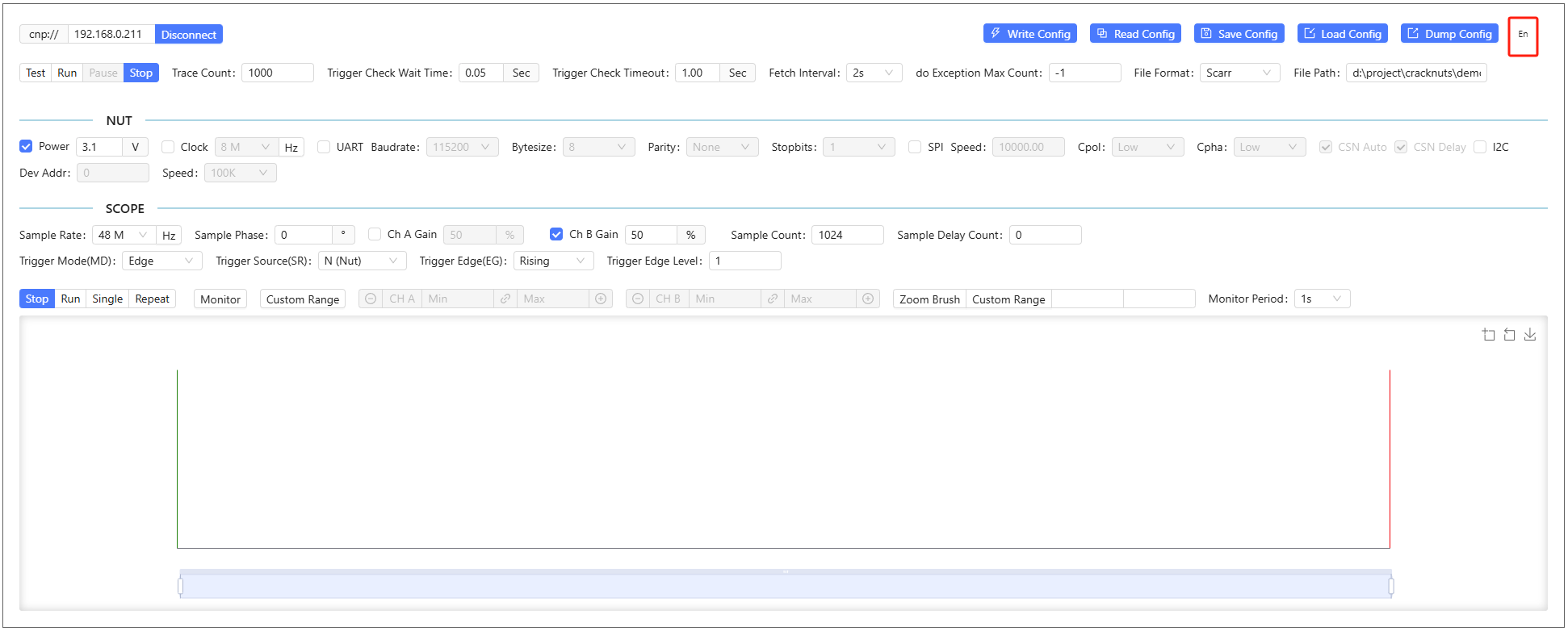
语言切换
控制面板在第一次使用时,默认界面展示的是英文,用户可以通过面板右上角的语言切换按钮进行切换,切换后对所有Jupyter Notebooke生效。
Jupyter默认工作目录配置
通过cracknuts lab命令启动的Jupter lab实例,可以通过如下命令配置默认的工作空间,保证用户无论在哪个目录下执行这个命令都能从工作空间启动。
cracknuts config set lab.workspace
曲线数据集
注:本文设计的波形数据可在 https://pan.baidu.com/s/1PXyKqeTfemepZ-wD9gDwYQ?pwd=2cda 下载。
数据格式介绍
TraceDataset是CrackNuts采集的波形数据管理类,他以zarr作为默认存储格式,以文件夹形式进行存储。他的结构如下:
-
traces:
- directory.zarr/X/Y/traces
-
data:
- directory.zarr/X/Y/ciphertext
- directory.zarr/X/Y/plaintext
- (optional) directory.zarr/X/Y/key
- (optional) directory.zarr/X/Y/extended
-
曲线和数据信息分别存储在
/X/Y/traces和/X/Y/<data>路径下。 -
在存储功耗信号时,
/X/YX固定为0,Y作为通道标识,例如第一个通道,则路径为/0/0/ -
在存储电磁信号时,
/X/Y是电磁侧信道测量的逻辑坐标。 -
其他公共MetaData信息存储在数据根路径的metadata属性中,包含:
- CrackNuts版本信息
- 数据创建时间
当使用 numpy 作为存储格式时,曲线数据和数据信息分别进行存储在一个名称包含.npy后缀的文件夹中。他的目录接口如下:
-
traces:
- directory/trace.npy
-
data:
- directory/ciphertext.npy
- directory/plaintext.npy
- (optional) directory/key.npy
- (optional) directory/extend.npy
-
曲线存储在根目录下的trace.npy文件下,该文件是numpy格式的保存格式,他是一个三维数组。
-
在存储功耗信号时,第一个维度为默认值0,第二个维度为通道索引,第三维度存储的是曲线数据
-
在存储电磁数据时,第一个和第二个维度分别是电磁的坐标
X Y坐标信息 -
数据信息则以与曲线同样的格式存储在相对应的
<data>.npy文件中 -
其他元信息存储在
metadata.json文件中
数据集的基础使用
数据集不需要用户自己创建,采集到的波形数据即为该格式的数据。用户可以通过TraceDataset.load方法加载已经采集的波形数据。
ZarrTraceDataset
默认情况下 TraceDataset 使用 zarr 作为存储格式,用户可使用 ZarrTraceDataset 类加载数据集:
from cracknuts.trace import ZarrTraceDataset
trace_path = r'D:\project\cracknuts\demo\jupyter\dataset\20250521110621(aes).zarr'
zarr_trace = ZarrTraceDataset.load(trace_path)
zarr_trace.info() # 打印数据集的基本信息
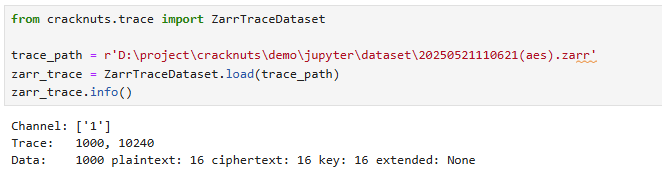
trace = zarr_trace.trace
trace[0, :1] # 获取第一个通道的第一条曲线

上述代码中,zarr_trace.trace: 这里的 trace 是一个特殊的属性,他支持两级的切片操作,第一个切片为通道索引、第二个切片为曲线索引。
他支持类似numpy的高级索引。
trace, data_array = zarr_trace.trace_data[:2, :2] # 获取其两通道的前两条曲线
print(trace.shape)
data_array[0][0] # 第一通道的第一条曲线的数据
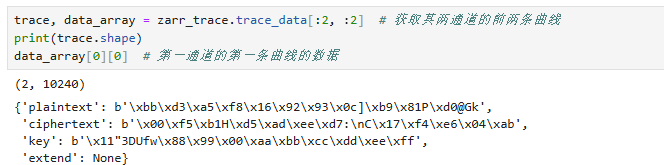
上述代码中,zarr_trace.trace_data[:2, :2]:这里的trace_data也是类似 trace 的支持切片操作的特殊属性,他返回的内容包括数据信息字典的数组,这个数据信息数组是一个二维对象数组,第一个维度是通道索引、第二个维度是曲线索引。
如果你对zarr格式较为熟悉,您可以直接过去该数据集对应的 zarr 格式数据对象:
origin_zarr = zarr_trace.get_origin_data()
origin_zarr.info
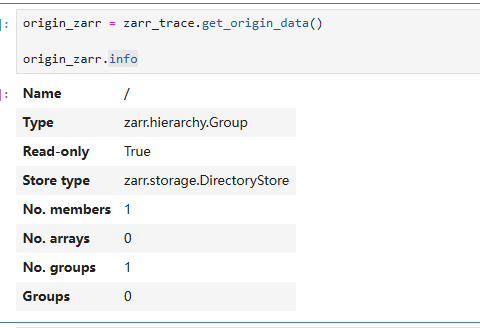
当然,您也可以直接使用zarr打开数据文件:
import zarr
trace_path = r'D:\project\cracknuts\demo\jupyter\dataset\20250521110621(aes).zarr'
zarr_trace = zarr.open(trace_path)
zarr_trace.info
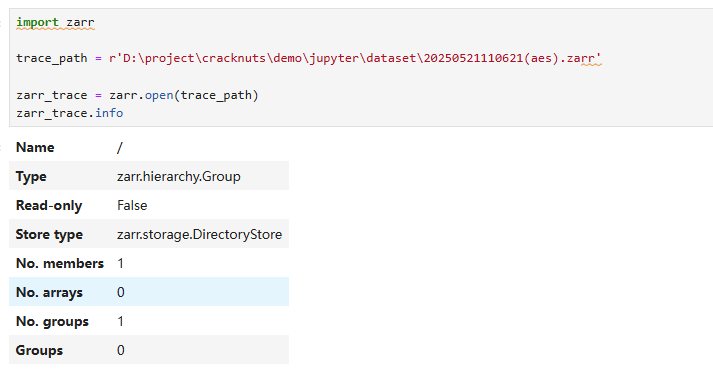
trace = zarr_trace['/0/0/traces']
trace.shape


NumpyTraceDataset
如果您在采集波形数据时,通过界面指定了存储格式,你可以得到以 numpy 为存储格式的数据集文件。

numpy 格式的数据集文件可以通过 NumpyDataset 类来进行加载:
from cracknuts.trace import NumpyTraceDataset
trace_path = r'D:\project\cracknuts\demo\jupyter\dataset\20250812145028(aes).npy'
trace_numpy = NumpyTraceDataset.load(trace_path)
trace_numpy.info()
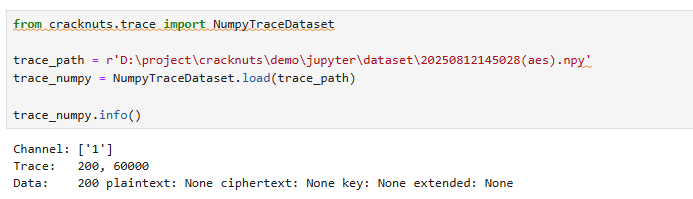
trace = trace_numpy.trace
trace[0, :1] # 获取第一个通道的第一条曲线

上述代码中,trace_numpy.trace: 这里的 trace 是一个特殊的属性,他支持两级的切片操作,第一个切片为通道索引、第二个切片为曲线索引。
他支持类似numpy的高级索引。
trace, data_array = trace_numpy.trace_data[:2, :2] # 获取其两通道的前两条曲线
print(trace.shape)
data_array[0][0] # 第一通道的第一条曲线的数据
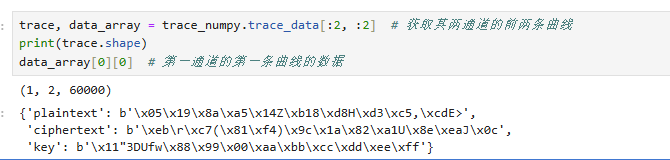
上述代码中,trace_numpy.trace_data[:2, :2]:这里的trace_data也是类似 trace 的支持切片操作的特殊属性,他返回的内容包括数据信息字典的数组,这个数据信息数组是一个二维对象数组,第一个维度是通道索引、第二个维度是曲线索引。
如果你对numpy格式较为熟悉,您可以直接过去该数据集对应的 numpy 格式数据对象:
import numpy as np
trace_path = r'D:\project\cracknuts\demo\jupyter\dataset\20250812145028(aes).npy\trace.npy' # 这里演示的是曲线数据,同样的也可以加载plaintext.npy 来加载明文数据
trace_numpy = np.load(trace_path)
trace_numpy.shape

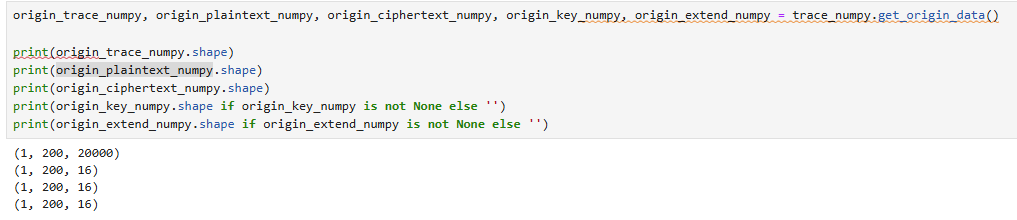
origin_trace_numpy, origin_plaintext_numpy, origin_ciphertext_numpy, origin_key_numpy, origin_extend_numpy = trace_numpy.get_origin_data()
print(origin_trace_numpy.shape)
print(origin_plaintext_numpy.shape)
print(origin_ciphertext_numpy.shape)
print(origin_key_numpy.shape if origin_key_numpy is not None else '')
print(origin_extend_numpy.shape if origin_extend_numpy is not None else '')
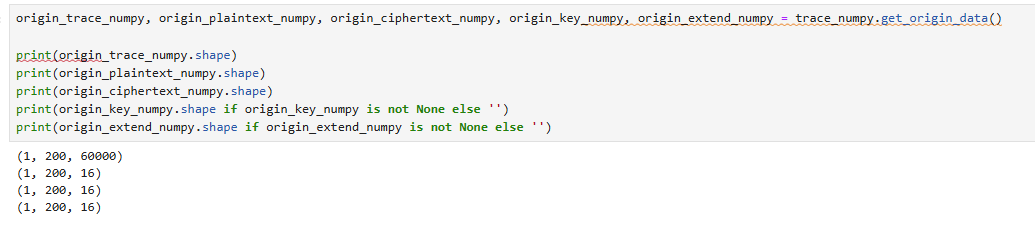
当然,您也可以直接使用numpy打开数据文件:
import numpy as np
trace_path = r'D:\project\cracknuts\demo\jupyter\dataset\20250812145028(aes).npy\trace.npy' # 这里演示的是曲线数据,同样的也可以加载plaintext.npy 来加载明文数据
trace_numpy = np.load(trace_path)
trace_numpy.shape
相关性数据集(squirrel库分析结果)
如果您使用cracknuts-squirrel库进行了相关性、CPA等分析,他可以产生一个最终的相关性矩阵,该数据同样采用zarr作为存储格式,其格式如下:
-
correlation:
- directory.zarr/X/Y/correlation
-
/X/Y固定为/0/0 -
correlation 中存储的是一个 三维数组,
- 当计算相关性时,第一个维度为 计算相关性的明文或密文的索引,第二个维度为 曲线数据点索引,第三个为 相关性曲线数据
- 当CPA分析时,第一个维度为猜测密钥的索引,第二个为密钥的比特位索引,第三个为 相关性曲线数据
更多详细内容,请参考 squirrel 文档。
日志配置
默认情况下,使用CrackNuts时,日志会打印到当前控制台,如果是Jupyter则会打印到运行单元格的下方,这些日志可以方便用户调试程序排查问题。

日志级别配置
CrackNuts默认的日志是warning级别,只打印必要的警告和错误信息,如果用户需要更详细的诸如发送的数据等信息可以通过以下方式修改日志级别为info来实现:
from cracknuts import logger
logger.set_level('info')

或者更加详细,把日志级别改成debug,但是这样打印信息会非常多,使用时需要注意:
from cracknuts import logger
logger.set_level('debug')
日志打印位置配置
有的时候,尤其是在能量轨迹采集过程中,会有有大量的日志打印,此时日志打印在控制台或者Jupyter Notebook中,会使得Jupyter页面变得非常长,难以使用,此时可以通过以下代码把日志重定向到文件,在通过其他工具进行日志的检查。
from cracknuts import logger
logger.handler_to_file(r"d:\a.log")
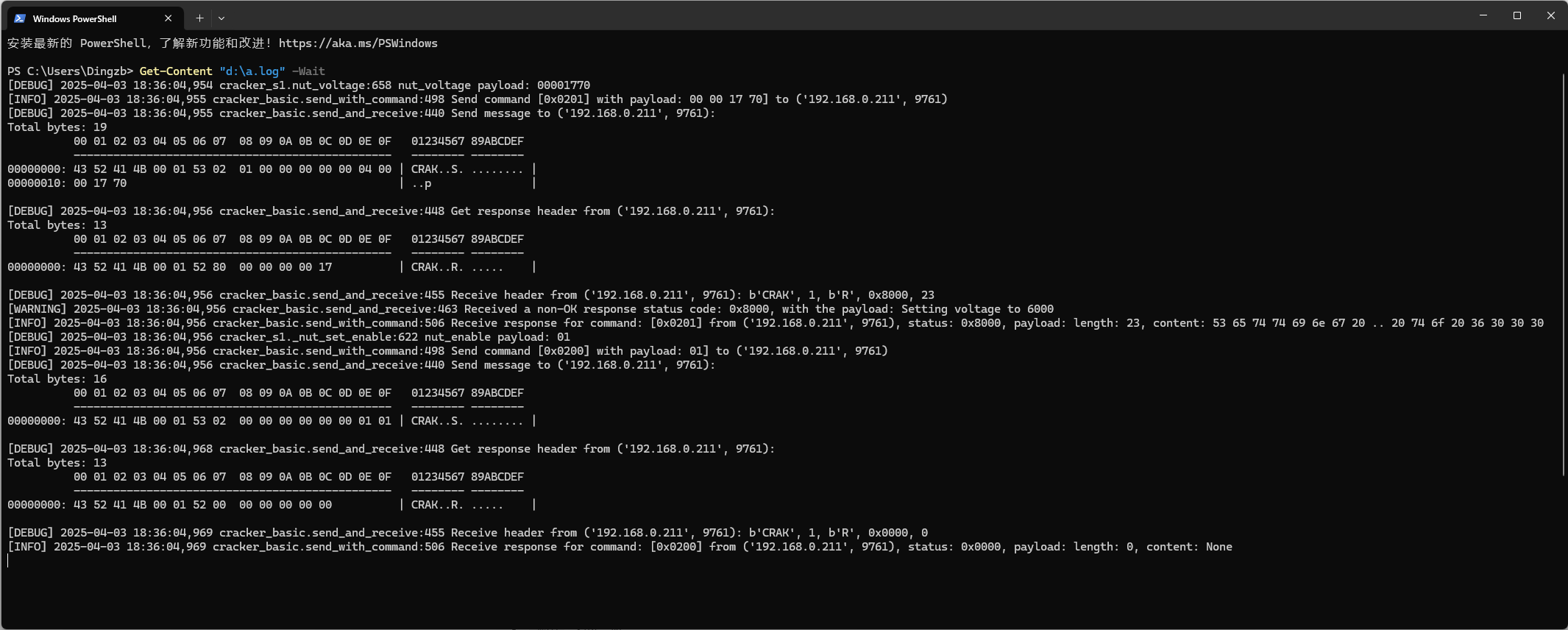
配置后可以通过任意文本编辑器打开日志文件进行检查:
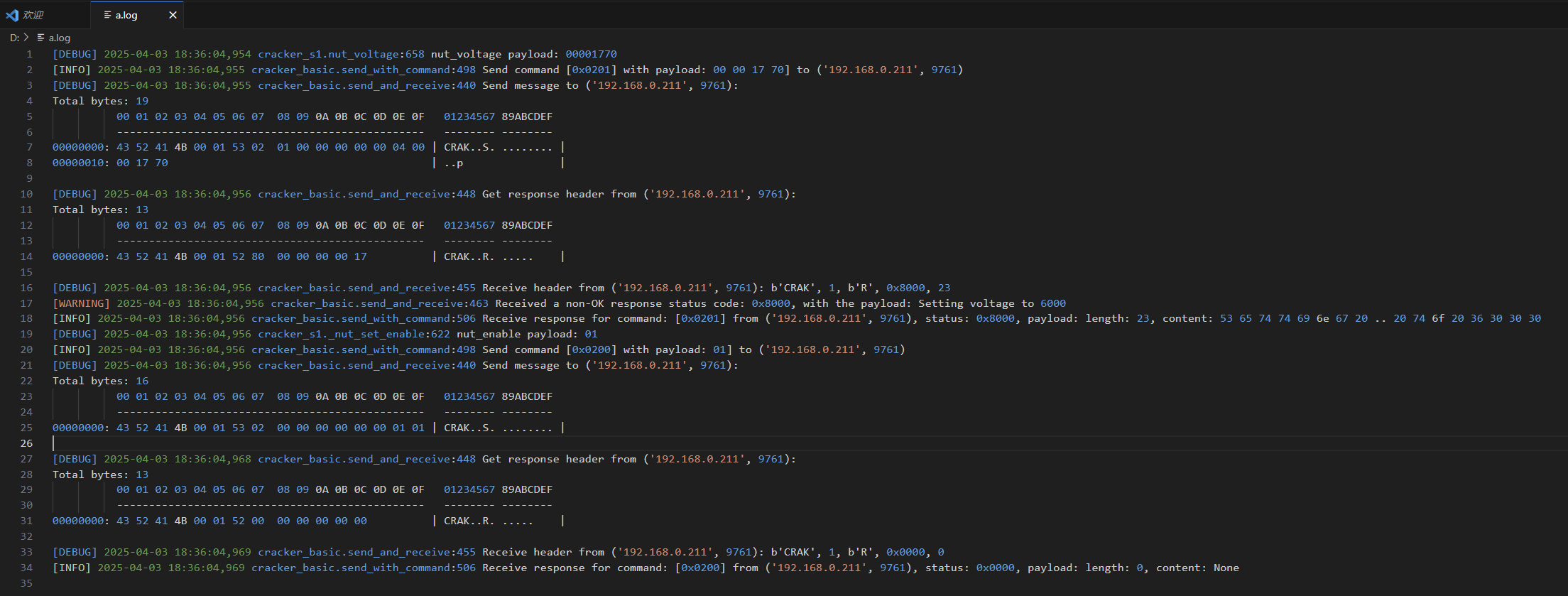
当前Linux或者MacOS用户可以通过tail -f的形式实时监控日志打印,Windows 用户可以通过在Powershell中使用Get-Content "d:\a.log" -Wait命令实现tail效果
更改 Cracker IP地址
如果你是将Cracker接入到已有的以太网中,需要该以太网的IP网络属于192.168.0.0/24这个网络,如果现有网络不在这个网段,则需要修改Cracker的IP。您需要先通过直连方式连接到设备在通过上位机SDK进行IP修改。
打开CrackNuts环境,启动Python 然后在执行如下代码进行IP修改:
import cracknuts as cn
s1 = cn.new_cracker('192.168.0.10')
s1.connect()
s1.get_operator().set_ip('192.168.0.251', '255.255.255.0', '192.168.0.1') # 此处IP地址及掩码、网关等需要修改为您的目标网络的允许的配置
执行成功后,Cracker设备的显示屏上会显示修改后的IP地址。